Понеже предлагаме “GPU сървъри за Машинно Обучение” хората често ни питат, каква е разликата между “Machine Learning” и “Deep Learning” – отговорът е “Не се различава”. Machine Learning (машинно обучение) е инструмент, който се използва за обучението на Artificial Intelligence (Изкуствен интелект). Deep Learning е просто един от начините, използвани при машинното обучение. В тази статия ще обсъдим различните методи на обучение, но първо кратко обяснение на това, как работи Machine Learning.
Как работи Machine Learning
1. Как се взема решение
Machine learning работи, като постоянно променя стойностите (тежестта) на някой от характеристиките на входящата информация. След като характеристика (вид специфична черта) е определена от алгоритъма за важна, на нея и се задава цифрова стойност (тежест) и се добавя към списък с важни характеристики. След като всяка важна характеристика е определена и е зададена стойност за нея, се изчислява краен резултат, ако този резултат е над определен праг (граница), тогава алгоритъмът прави своето предположение или класифицира резултата.
Най-лесният начин да го обясним е като го сравним с броенето на карти при Black Jack. Най-разпространеният начин е техника наречена “Голяма – малка карта”. При нея задавате стойност от +1 на всяка карта от 2 до 6, нула на всяка 7-ца, 8-ца и 9-ка, и – 1 на J,Q,K,A. Когато картите бъдат раздадени се изчислява резултатът. Да кажем, че в началото на играта вие получавате 5-ца, а дилърът 6-ца, то тогава моментният резултат е +2, което означава, че има по-голям шанс следващата карта да е голяма. Колкото по-голям е сборът, толкова е по-голям шанса да се падне J, Q ,K, A. Същото нещо се прави и при машинното обучение, но с много повече променливи.
2. Проверка за грешки
Ако използвате supervised ML, след като се вземе решение, то се сравнява с наличната информация, за която знаете, че алгоритъмът се справя добре. Ако не прилагате този метод, тогава ще използвате само част от информацията, с която разполагате за трениране на алгоритъма и след това ще използвате останалата част, за да проверите дали работи. Ако не сте постигнали желаният резултат, продължавате към стъпка три.
3. Оптимизиране на модела
При тази стъпка връщаме алгоритъм на позиция едно, където той променя тежестта на някои характеристики, както и тяхната максимална стойност. В същото време ще промени и прагът, който трябва да премине, за да направи предположение или да даде отговор на въпроса. Този цикъл ще се повтаря, докато се постигне желаният резултат.
Различните видове Machine learning
Спрямо степента на човешката намеса, машинното обучение може да бъде supervised (обучение с надзирател), unsupervised (без надзирател) или смесено обучение.
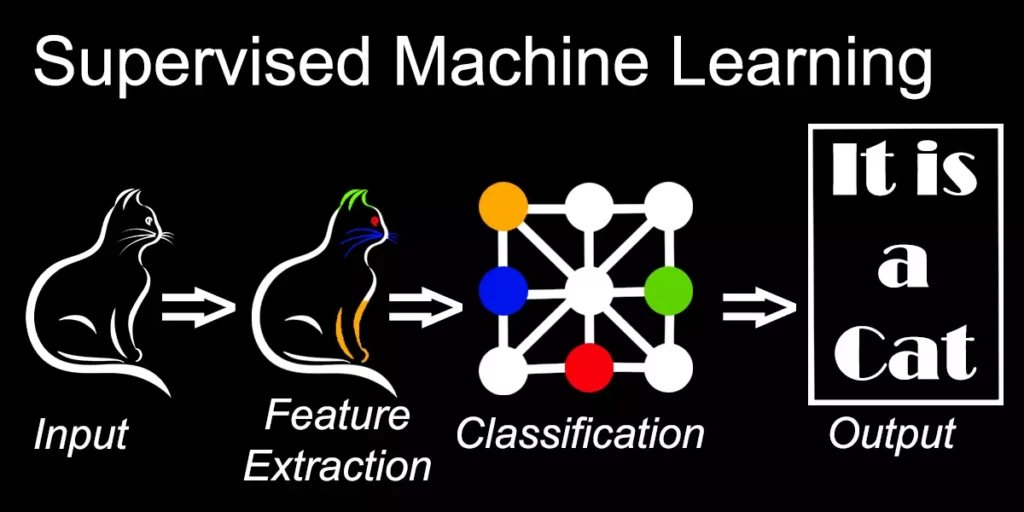
Supervised Machine Learning (Обучение с надзирател)
При този процес на алгоритъма се предоставя маркирана входяща информация, както и желания резултат. От алгоритъма се очаква да се научи сам да достига до верния отговор. За целта той сам трябва да зададе стойности за различните характеристики, да реши колко са важни (като промени максималната им стойност) и да направи изчисленията. След като това се случи, човек проверява дали алгоритъмът не е прекалено настроен за специфичната информация (over/under fitted) на този data set (масив от информация), което ще покаже дали ще може да се справи с други data sets, които той не е виждал досега.
Unsupervised Machine Learning (Самостоятелно обучение)
При този модел на алгоритъма е предоставена немаркирана входяща информация и не му е зададена точна задача. Тук целта е да се открият скрити прилики или модели на действие и благодарение на тях да се групира информацията. Това е перфектният модел за работа по големи масиви с информация, които се използват за cross-selling, препоръки на филми, разпознаване на снимки и други задачи, при които е необходимо голям обем информация да се сортира бързо.
Semi-supervised learning (Смесено обучение)
Този модел е компилация от предните два, като при него се предоставя малко маркирана информация, върху която алгоритъмът се обучава и разпознава как да я маркира. След това вече може да пристъпите към голямо количество информация, която той да маркира сам, като прилага наученото преди това, и да се научи да изпълнява и другите желани задачи. Това решава проблема с липсата на достатъчно маркирана информация или ако маркирането на информацията би било прекалено скъпо.
Reinforcement machine learning (Позитивно обучение)
При този модел не се предоставя предварителна тренировъчна информация – алгоритъмът се учи в движение от информацията, с която разполага в момента. Когато алгоритъмът направи нещо, което се счита за полезно, му се дава положителна (позитивна) обратна връзка. Мислете, как се тренира куче – ако му издадете команда и то направи нещо добро, обикновено му давате бисквитка или нещо, което то харесва, и затова следващия път, когато то изпадне в същата ситуация, то знае да повтори същото нещо. И в бъдеще, ако видите google snippet и той е полезен, натиснете бутона “да това беше полезно”, за да го похвалите. 🙂
Видове алгоритми за Machine Learning
Според използваните алгоритми machine learning може да бъде разделено на такива използващи:
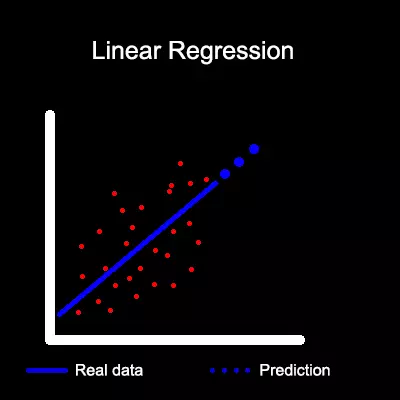
Linear regression (Линейна регресия)
Този алгоритъм се използва за прогнозиране стойностите на дадена единица, като се сравнява с историческите и взаимоотношенията ѝ с друга единица. Това е полезно за предвиждането на промени в цените на различни продукти.
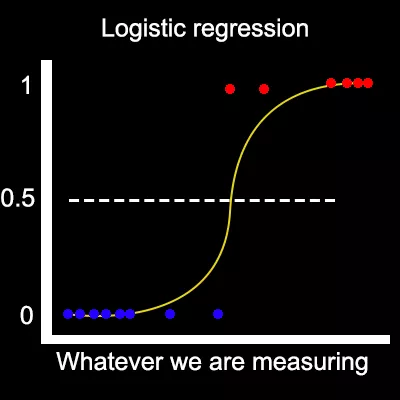
Logistic regression (Логистична регресия)
Този вид регресия се използва за даването на “Да/Не” отговори.
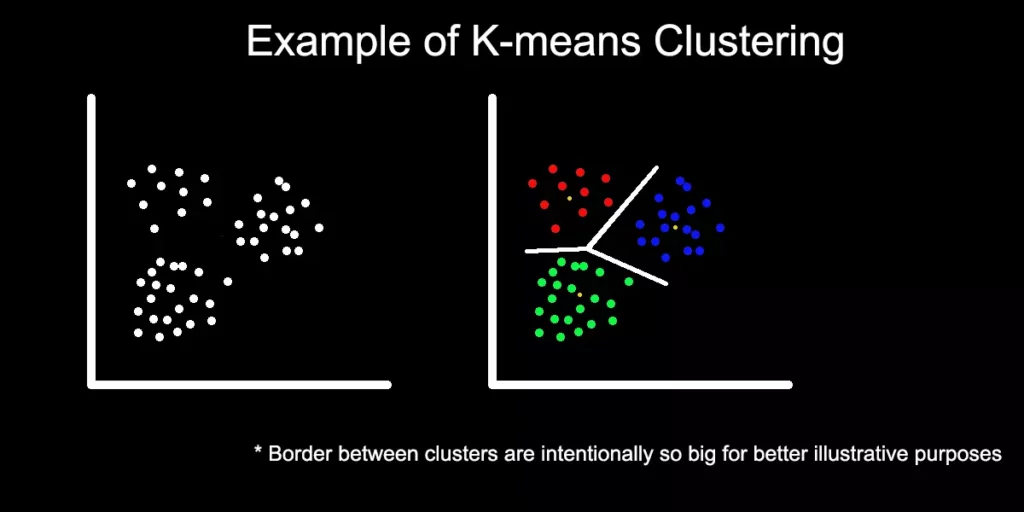
Clustering (Групиране)
Този вид “самообучение” помага на учените да идентифицират и групират информацията на база скрити модели и прилики, които специалистите са пренебрегнали или не са знаели да търсят.
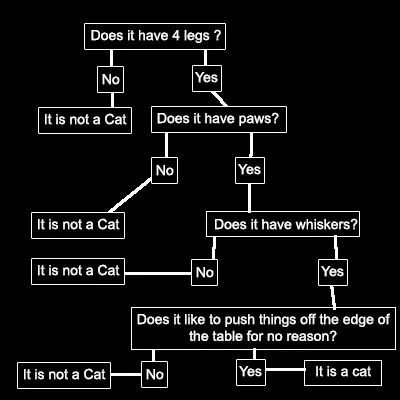
Decision trees (Дървовидни)
Този алгоритъм може да се използва, както за класифициране на данни, така и за прогнозиране на числени стойности. Носи името си, защото е изграден от много взаимосвързани решения, които приличат на клони на дърво, в които е лесно да се проверява за грешки и да се правят промени.
Neural Network (Невронна мрежа)
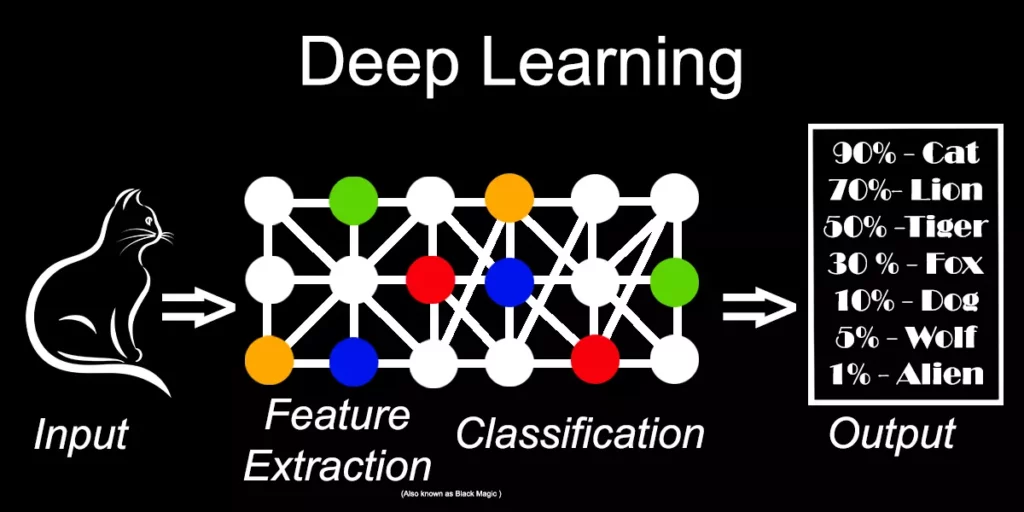
Тя може да приема всякакъв вид информация и е най-добра за задачи, за които не се очаква точен резултат. Често те са сложни за обяснение и сравнение, но учудващо ефективни за някои сложни задачи. Невронните мрежи използват различни разклонения, където изходящата информация на единия възел (node) е входяща информация на друг, също като дървовидната структура, но за разлика от нея където отговорът е винаги “ДА” или “НЕ”, при невронните мрежи изходящата информация е сложна и има нужда от още обработка. Всеки път, когато обработената информация достигне определен праг в един възел, той се активира и подава информацията на следващия възел в невронната мрежа. Точно тук идва и терминът “Deep Learning”, ако една невронна мрежа се състой от повече от 3 такива поредни възела (разклонения), то тя се счита за Deep Neural Network (дълбока невронна мрежа), а алгоритъмът “Deep Learning”.
Проблеми, с които трябва да се справи машинното обучение
Като всяка нова технология, Machine learning трябва да се справи с някои проблеми преди да може да продължи да се развива. В този случай те са по-скоро от етична гледна точка, отколкото от ограниченията на технологията.
Смъртоносен изкуствен интелект (Technological singularity)
Това е сюжетна линия на много научно-фантастични филми. Как Изкуственият интелект става толкова напреднал, че ефективно става по-умен от всеки човек, вследствие на което решава да ни използва за гориво (Матрицата), да ни убие или асимилира (Стар Трек) или да реши, че нелогичното ни поведение е вредно за нас и трябва да ни пороби, за да ни спаси от нас самите (Аз, роботът). Реалността е, че сме доста далече от това ниво, но дори и да бяхме близо щяхме да имаме някакъв вид защита от това роботите да се обърнат срещу нас. Дори и един от най-известните автори на научна-фантастика Айзък Азимов предвижда трите закона на роботиката, които гласят:
1. Роботът не може да нарани човешко същество или чрез бездействието си да позволи човек да бъде наранен
2. Роботът трябва да изпълнява всяка заповед, дадена му от човека, с изключение, когато това противоречи на първият закон.
3. Роботът трябва да се отбранява и защитава, освен ако това не противоречи на предишните два закона.
Runaround – Автор: Айзък Азимов. Написана през 1942.
След като обсъдихме научната-фантастика е време да се върнем в наши дни и да разгледаме малко по-реалистични въпроси. Кой е отговорен за пътни инциденти, предизвикани от автомобил на автопилот? Шофьорът или производителят на автомобила?
Изкривена информация и дискриминация
Можем да се съгласим, че повечето компании, разработващи Изкуствен интелект, имат добри намерения когато започват проекта си, но понякога нещата не сработват както ни се иска. Изкуственият интелект и машинното обучение са толкова добри, колкото е добра информацията, на която са им дали да се учат. Понякога тази информация е неумишлено изкривена, поради ограничения от закона или региона, от където идва.
Например, ако живеете в район, където има една голяма група от хората с подобни характеристики и много други с различни характеристики, алгоритъмът ще се справя по-добре с разпознаването на информация за преобладаващата група, отколкото с информация за малките групи, защото ще разполага с повече информация за голямата група, на която да се обучава и тренира. Понякога законите в държавата забраняват изцяло събирането на информация за хората и тя може да бъде събрана единствено, ако човек доброволно я предостави. При тези ситуации някои от групите са по-склонни да предоставят информация за себе си. И естествено, понякога информацията е изкривена, поради нашата природа и мироглед. Каквато и да е причината, понякога Изкуственият интелект може да дискриминира хората.
Всеки подобен пример показва на инженерите, че информацията им трябва да идва от много на брой и разнообразни източници, за да е полезна, като някои от тях дори дават свободен достъп на всеки да предоставя информация за техните алгоритми за обучение, но и това си има своите недостатъци
Privacy (Уединение)
Както споменахме, законите са една от причините инженерите да имат ограничен достъп до информация. Това се дължи на нарастващата загриженост на хората относно това за какво се използват техните лични данни. Този обществен дебат започна след като стана ясно, че информация, събирана с години, е била използвана за лични облаги или за политически цели. В отговор на това повечето големи държави приеха или са в процес на приемане на закони за защита на личната информация на потребителите. Конкретно Европейският съюз прие Общ регламент за защита на данните (GDPR), а щата Калифорния прие Закон за защита на личната информация на потребителя (CCPA). Това са едни от първите такива закони, които се прилагат. Те изискват бизнесът да информира потребителя за данните, които събират от потребителя и как ще ги използват. Те също така изискват от компанията да предостави ЛЕСЕН начин за отказ събирането на такава информация.
Това са само от някои от етичните и законови проблеми, които трябва да преодолее машинното обучение.
За какво се използва Machine Learning в реалния живот
Автопилот на коли
Една от най-разпространените функции на машинното обучение е при самоуправляващите се автомобили. Тук алгоритъмът използва информацията от LIDAR-а, Радара и видео камерите си, за да изчисли разстоянието и скоростта на различните обекти на пътя, след което взема решение на база предходен опит.
Препоръки
Тук се използва групиране, за да се направят препоръки, какво би могло да ви е интересно да гледате или какво би могло да ви допадне да си купите. Тук се използва историята на вашите покупки или гледани филми и се сравнява с други потребители, които имат подобна история, и на база тази информация се прави препоръка.
Софтуер за разпознаване на гласове
Всички сме свикнали да диктуваме съобщенията си, когато шофираме или да записваме неща в календара си без да докосваме телефона си, но рядко се замисляме как това е възможно. Тук се използва Machine Learning, за да се научи изкуственият интелект да разпознава стандартни фрази, като ги сравнява с такива, които са произнесени ясно и правилно. След, като дадена фраза се срещне достатъчно пъти, за да се потвърди че алгоритъмът я разпознава правилно, тя се добавя, към основната база за този термин, така, когато някой с диалект произнесе фразата, алгоритъмът има повече точки за сравнение, защото всички сме съгласни, че софиянец, ще произнесе думата “Мляко” различно от русенец. 🙂
Борсова търговия
Като използва машинно обучение за прогнозиране на промени в цените, изкуственият интелект прави милиони сделки всеки ден. Този начин на търговия е толкова важен за някои компании, че те са готови да плащат милиони, за да могат да поставят компютърната си техника възможно най-близо до стоковата борса, защото когато става дума за търговия, направена с помощта на Изкуствен интелект, всяка милисекунда е от значение.
Засичане на измами
Всяка банка използва машинно обучение, за да засича съмнителни поръчки, като сравнява дали мястото, от което е направена поръчката съвпада с обичайните ви покупки. Нормално, ако човек, който живее в Русе и редовно пазарува хранителни продукти с кредитната си карта, изведнъж започне да купува бяла и черна техника в Мелник, тази транзакция ще бъде блокирана и човекът, ще получи обаждане от Банката, за да потвърди плащането.
Заключение
Machine learning е част от нашето ежедневие независимо дали си даваме сметка или не. Значението му само ще нараства, а задачите, които изпълнява, ще стават все по-сложни. Респективно с тези по-сложни задачи, ще растат и хардуерните изисквания към сървърите, на които се обучава алгоритъмът. Ние от MaxCloudON можем да ви помогне с това. Нашите GPU servers са снабдени с мощни видео карти с много VRAM, което ви позволява да работите и на най-големите data set-ове, изисквани за работа с алгоритми за разпознаване на изображения и видео. Също така ви предлагаме мощни процесори, много RAM, както и бързо дисково пространство. Ако сте заинтересовани от нашите сървъри проверете нашите цени или прочетете защо са конфигурирани по този начин.